


3社共用電話帳一括登録QRコード [PC]
ドコモ、au、SBM3社共用電話帳一括登録QRコードについての考察。
3社共用のプロフィールQRコードは、「QRのススメ」さんの「プロフィール上級」で作れるが、au・SBM機ではメモ欄にドコモ用文字列が登録されてしまう(メモ欄のみ削除すれば問題はない)。
メモリダイヤル一括登録用タグは「ドコモ」と「au・SBM」で仕様が異なるため、3社共用コードを生成するには2種類のタグを埋めこむ必要がある(au・SBMにも微妙な差はあるがほぼ共通)。「プロフィール上級」で生成されるQRコードには、以下の文字列が埋めこまれている。
MEMORY:(メモ文字列) MECARD:N:(姓),(名);SOUND:(姓読み),(名読み);TEL:(電話番号1);TEL:(電話番号2);EMAIL:(メールアドレス1);EMAIL:(メールアドレス2);NOTE:(メモ文字列) ;;
NAME1:(姓名)
NAME2:(姓名読み)
TEL1:(電話番号1)
MAIL1:(メールアドレス1)
TEL2:(電話番号2)
MAIL2:(メールアドレス2)
上記手法では、au・SBMメモ用タグ内にドコモ用のメモリダイヤル一括登録文字列が埋めこまれている。このため、au・SBM機ではメモ欄に余計な文字が入ってしまうわけだ。
au・SBMでいちいちメモ欄を消すのが面倒ならば書式を以下のように変え、QRコード生成サイト(ソフト)でフリーテキスト変換するのも手。
MEMORY:(メモ文字列)
NAME1:(姓名)
NAME2:(姓名読み)
TEL1:(電話番号1)
MAIL1:(メールアドレス1)
TEL2:(電話番号2)
MAIL2:(メールアドレス2)
MECARD:N:(姓),(名);SOUND:(姓読み),(名読み);TEL:(電話番号1);TEL:(電話番号2);EMAIL:(メールアドレス1);EMAIL:(メールアドレス2);NOTE:(メモ文字列) ;;
こうすると、au・SBMでのメモ欄問題がなくなる。ドコモ機で読ませた場合は、「au・SBM用文字列」の後に表示される「電話帳登録」をクリックすれば一括登録可能だ。
…… 備考 ……
●ドコモのメモリダイヤル一括登録用タグ
「MECARD:」以降がメモリダイヤル一括登録用文字列として認識される。セパレータは「:」(セミコロン)で、途中に改行を挿入せず1ラインで記述。電話番号やメールアドレスを複数設定したい場合は、「TEL:」や「EMAIL:」タグを複数記述すればよい。
N:(姓,名)
SOUND:(姓読み),(名読み)
TEL:(電話番号)
TEL-AV:(テレビ電話番号)
EMAIL:(メールアドレス)
NOTE:(メモ)
BODY:(誕生日)
ADR:(住所)
URL:(ホームページURL)
NICKNAME:(ニックネーム)
●au、SBMのメモリダイヤル一括登録用タグ
以下の「タグ:パラメータ」で構成され、セパレータはCR/LF。「MEMORY」タグで始まっていないと、メモリダイヤル一括登録用文字列として認識されない。
MEMORY:(メモ文字列)
NAME1:(姓名)
NAME2:(姓名読み)
MAIL1:(メールアドレス1)
MAIL2:(メールアドレス2)
MAIL3:(メールアドレス3)
TEL1:(電話番号1)
TEL2:(電話番号2)
TEL3:(電話番号3)
ADD:(住所)※auのみ
●各社QRコードフォーマット資料は以下のサイトで公開されている
ドコモ→http://www.nttdocomo.co.jp/service/imode/make/content/barcode/function/application/index.html
au→http://www.au.kddi.com/ezfactory/tec/two_dimensions/
SBM(要会員登録)→http://creation.mb.softbank.jp/
【プチ告知】
『任天堂公式ガイドブック メイドイン俺 ゲームツクリエイターウルトラハンドブック』がようやく発売の運びとなりました。21010netで一部ページをお読みいただけます。ひと月半でこのボリュームの本を書き上げること自体がかなりキピシーわけですが、中でも120本近いダイヤモンドソフトAIの解析が一番キツかった……面白テク満載でおもしろかったけどww。
")
3社共用のプロフィールQRコードは、「QRのススメ」さんの「プロフィール上級」で作れるが、au・SBM機ではメモ欄にドコモ用文字列が登録されてしまう(メモ欄のみ削除すれば問題はない)。
メモリダイヤル一括登録用タグは「ドコモ」と「au・SBM」で仕様が異なるため、3社共用コードを生成するには2種類のタグを埋めこむ必要がある(au・SBMにも微妙な差はあるがほぼ共通)。「プロフィール上級」で生成されるQRコードには、以下の文字列が埋めこまれている。
MEMORY:(メモ文字列) MECARD:N:(姓),(名);SOUND:(姓読み),(名読み);TEL:(電話番号1);TEL:(電話番号2);EMAIL:(メールアドレス1);EMAIL:(メールアドレス2);NOTE:(メモ文字列) ;;
NAME1:(姓名)
NAME2:(姓名読み)
TEL1:(電話番号1)
MAIL1:(メールアドレス1)
TEL2:(電話番号2)
MAIL2:(メールアドレス2)
上記手法では、au・SBMメモ用タグ内にドコモ用のメモリダイヤル一括登録文字列が埋めこまれている。このため、au・SBM機ではメモ欄に余計な文字が入ってしまうわけだ。
au・SBMでいちいちメモ欄を消すのが面倒ならば書式を以下のように変え、QRコード生成サイト(ソフト)でフリーテキスト変換するのも手。
MEMORY:(メモ文字列)
NAME1:(姓名)
NAME2:(姓名読み)
TEL1:(電話番号1)
MAIL1:(メールアドレス1)
TEL2:(電話番号2)
MAIL2:(メールアドレス2)
MECARD:N:(姓),(名);SOUND:(姓読み),(名読み);TEL:(電話番号1);TEL:(電話番号2);EMAIL:(メールアドレス1);EMAIL:(メールアドレス2);NOTE:(メモ文字列) ;;
こうすると、au・SBMでのメモ欄問題がなくなる。ドコモ機で読ませた場合は、「au・SBM用文字列」の後に表示される「電話帳登録」をクリックすれば一括登録可能だ。
…… 備考 ……
●ドコモのメモリダイヤル一括登録用タグ
「MECARD:」以降がメモリダイヤル一括登録用文字列として認識される。セパレータは「:」(セミコロン)で、途中に改行を挿入せず1ラインで記述。電話番号やメールアドレスを複数設定したい場合は、「TEL:」や「EMAIL:」タグを複数記述すればよい。
N:(姓,名)
SOUND:(姓読み),(名読み)
TEL:(電話番号)
TEL-AV:(テレビ電話番号)
EMAIL:(メールアドレス)
NOTE:(メモ)
BODY:(誕生日)
ADR:(住所)
URL:(ホームページURL)
NICKNAME:(ニックネーム)
●au、SBMのメモリダイヤル一括登録用タグ
以下の「タグ:パラメータ」で構成され、セパレータはCR/LF。「MEMORY」タグで始まっていないと、メモリダイヤル一括登録用文字列として認識されない。
MEMORY:(メモ文字列)
NAME1:(姓名)
NAME2:(姓名読み)
MAIL1:(メールアドレス1)
MAIL2:(メールアドレス2)
MAIL3:(メールアドレス3)
TEL1:(電話番号1)
TEL2:(電話番号2)
TEL3:(電話番号3)
ADD:(住所)※auのみ
●各社QRコードフォーマット資料は以下のサイトで公開されている
ドコモ→http://www.nttdocomo.co.jp/service/imode/make/content/barcode/function/application/index.html
au→http://www.au.kddi.com/ezfactory/tec/two_dimensions/
SBM(要会員登録)→http://creation.mb.softbank.jp/
【プチ告知】
『任天堂公式ガイドブック メイドイン俺 ゲームツクリエイターウルトラハンドブック』がようやく発売の運びとなりました。21010netで一部ページをお読みいただけます。ひと月半でこのボリュームの本を書き上げること自体がかなりキピシーわけですが、中でも120本近いダイヤモンドソフトAIの解析が一番キツかった……面白テク満載でおもしろかったけどww。
メイドイン俺―ゲームツクリエイターウルトラハンドブック (ワンダーライフスペシャル NINTENDO DS任天堂公式ガイドブック)
- 作者:
- 出版社/メーカー: 小学館
- 発売日: 2009/06
- メディア: ムック
電子ブックのカタログファイル編集 [PC]
電子ブック(EB)ソフトには収録辞書タイトル情報等が格納されている「CATALOG」というファイルがあり、catcump.exeを利用して編集すると「辞書タイトル変更」「辞書の削除・追加」が行える。アドエスのmicroSDにEBソフトを複数入れる際、重複する辞書を削るとデータ容量を節約することができる。以下、catdumpの入手・使用方法を記す。
【1】 EDICT SNAPSHOTからebutils/Windows 32bit(ebu-w32.lzh)を入手。
【2】 ebu-w32.lzhを展開し、CATDUMP.EXEを取り出す。ここではC:\BIN(ディレクトリ)を作成し、そこへ展開する。
【3】 スタートメニューの「ファイル名を指定して実行」を選択し、「cmd」と入力した後「OK」をクリック。コマンドプロンプトを起動し、EBデータ格納ドライブ・ディレクトリに移動する(ここではD:\EB_DICT\KAN_PIL_CHIE99にデータがあるものとする。パラメータは各自の環境に合わせて指定しよう)。
C:\Documents and Settings\username>d: D:\>cd \EB_DICT\KAN_PIL_CHIE99
【4】 dir[Enter]と入力し、CATALOGがあることを確認。
【5】 CATDUMPを使ってCATALOGファイルをテキスト化する。
D:\EB_DICT\KAN_PIL_CHIE99>C:\BIN\CATDUMP CATALOG > CATALOG.txt
【6】 CATALOG.txtをテキストエディタで開く。
; 電子ブック/EPWING カタログ内容 (generated by catdump v1.2pre) [Catalog] FileName = CATALOG Type = EB Books = 3 [Book] BookType = 0100 Title = "全漢字拡大版『漢字源』" Directory = "KANJIGEN" [Book] BookType = 0200 Title = "薬の事典『ピルブック』" Directory = "PILLBOOK" [Book] BookType = 0300 Title = "『知恵蔵』1999年版" Directory = "AGE01"
【7】 辞書タイトルを変えるなら「Title =」行を変更。一部辞書を削除したいなら不要な[Book]ブロックを削除して、その分「Books =」の値を減らす。以下はタイトル変更と『ピルブック』の削除を行った例(赤字が変更点)。
; 電子ブック/EPWING カタログ内容 (generated by catdump v1.2pre) [Catalog] FileName = CATALOG Type = EB Books = 2 [Book] BookType = 0100 Title = "漢字源" Directory = "KANJIGEN" この部分にあった『ピルブック』[Book]ブロックを削除 [Book] BookType = 0300 Title = "知恵蔵・1999年版" Directory = "AGE01"
【8】 【7】で変更を加えたCATALOG.txtを、catdumpでバイナリ化する。オリジナルのCATALOGファイルを事前にバックアップしておくのがおすすめ。
D:\EB_DICT\KAN_PIL_CHIE99>copy CATALOG CATALOG.bak 1 個のファイルをコピーしました。 D:\EB_DICT\KAN_PIL_CHIE99>C:\BIN\CATDUMP -u CATALOG.txt CATALOG
【9】 CATALOG変更前と後をEBWinで見比べてみよう。
変更前。辞書バーに注目(辞書名の頭3文字のみ表示されていて判別しづらい)
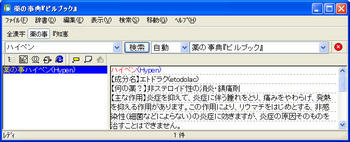
変更後(EBWinのファイルメニューで「辞書の再検索」を行うこと)
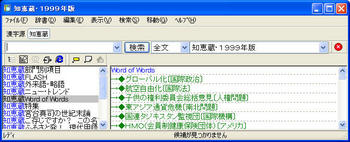
削除した『ピルブック』はCATALOGからは消えているが、辞書データ本体はHDD上にまだ残っている。不要ならPILLBOOKディレクトリを削除して構わない(辞書データ格納ディレクトリはCATALOG.txt内のDirectory=行に書かれている)。
【1】 EDICT SNAPSHOTからebutils/Windows 32bit(ebu-w32.lzh)を入手。
【2】 ebu-w32.lzhを展開し、CATDUMP.EXEを取り出す。ここではC:\BIN(ディレクトリ)を作成し、そこへ展開する。
【3】 スタートメニューの「ファイル名を指定して実行」を選択し、「cmd」と入力した後「OK」をクリック。コマンドプロンプトを起動し、EBデータ格納ドライブ・ディレクトリに移動する(ここではD:\EB_DICT\KAN_PIL_CHIE99にデータがあるものとする。パラメータは各自の環境に合わせて指定しよう)。
C:\Documents and Settings\username>d: D:\>cd \EB_DICT\KAN_PIL_CHIE99
【4】 dir[Enter]と入力し、CATALOGがあることを確認。
【5】 CATDUMPを使ってCATALOGファイルをテキスト化する。
D:\EB_DICT\KAN_PIL_CHIE99>C:\BIN\CATDUMP CATALOG > CATALOG.txt
【6】 CATALOG.txtをテキストエディタで開く。
; 電子ブック/EPWING カタログ内容 (generated by catdump v1.2pre) [Catalog] FileName = CATALOG Type = EB Books = 3 [Book] BookType = 0100 Title = "全漢字拡大版『漢字源』" Directory = "KANJIGEN" [Book] BookType = 0200 Title = "薬の事典『ピルブック』" Directory = "PILLBOOK" [Book] BookType = 0300 Title = "『知恵蔵』1999年版" Directory = "AGE01"
【7】 辞書タイトルを変えるなら「Title =」行を変更。一部辞書を削除したいなら不要な[Book]ブロックを削除して、その分「Books =」の値を減らす。以下はタイトル変更と『ピルブック』の削除を行った例(赤字が変更点)。
; 電子ブック/EPWING カタログ内容 (generated by catdump v1.2pre) [Catalog] FileName = CATALOG Type = EB Books = 2 [Book] BookType = 0100 Title = "漢字源" Directory = "KANJIGEN" この部分にあった『ピルブック』[Book]ブロックを削除 [Book] BookType = 0300 Title = "知恵蔵・1999年版" Directory = "AGE01"
【8】 【7】で変更を加えたCATALOG.txtを、catdumpでバイナリ化する。オリジナルのCATALOGファイルを事前にバックアップしておくのがおすすめ。
D:\EB_DICT\KAN_PIL_CHIE99>copy CATALOG CATALOG.bak 1 個のファイルをコピーしました。 D:\EB_DICT\KAN_PIL_CHIE99>C:\BIN\CATDUMP -u CATALOG.txt CATALOG
【9】 CATALOG変更前と後をEBWinで見比べてみよう。
変更前。辞書バーに注目(辞書名の頭3文字のみ表示されていて判別しづらい)
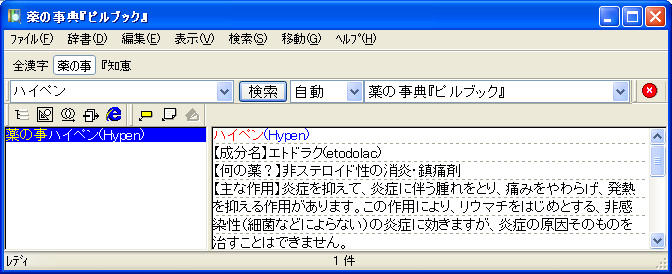
変更後(EBWinのファイルメニューで「辞書の再検索」を行うこと)
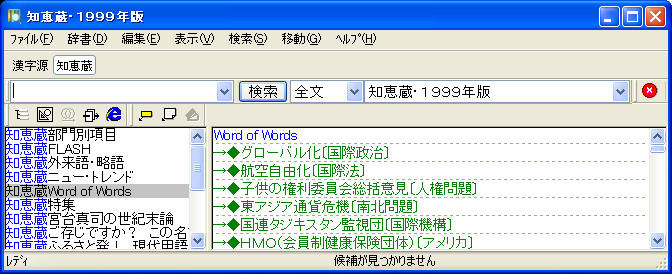
削除した『ピルブック』はCATALOGからは消えているが、辞書データ本体はHDD上にまだ残っている。不要ならPILLBOOKディレクトリを削除して構わない(辞書データ格納ディレクトリはCATALOG.txt内のDirectory=行に書かれている)。
電子ブックのデータを圧縮する [PC]
前のエントリで紹介したEBPocketは、ebzipで圧縮された電子ブックソフトをアクセスすることができる。無圧縮だとmicroSD容量を圧迫するのでデータサイズをコンパクトにしてしまおう。
【1】 EB Libraryのサイトから「バージョン 4.2.2 の Windows 用インストーラ」を入手、インストール。
【2】 スタートメニューの「ファイル名を指定して実行」を選択し、「cmd」と入力した後「OK」をクリック。コマンドプロンプトを起動し、EBデータ格納ドライブ・ディレクトリに移動する(ここではD:\EB_DICT\KAN_PIL_CHIE99にデータがあるものとする。パラメータは各自の環境に合わせて指定しよう)。
C:\Documents and Settings\username>d: D:\>cd \EB_DICT\KAN_PIL_CHIE99
【3】 コマンドプロンプトでebzipを用いてデータ圧縮。
D:\EB_DICT\KAN_PIL_CHIE99>"C:\Program Files\EB Library\bin\ebzip" -k -f -l 0 ==> D:\EB_DICT\KAN_PIL_CHIE99\.\KANJIGEN\START を圧縮 <== .\KANJIGEN\START.ebz に出力 2.3% 処理済み (2097152 / 91942912 バイト) ……中略…… 98.1% 処理済み (90177536 / 91942912 バイト) 完了 (91942912 / 91942912 バイト) 91942912 -> 24280019 バイト (26.4%) ==> D:\EB_DICT\KAN_PIL_CHIE99\.\PILLBOOK\START を圧縮 <== .\PILLBOOK\START.ebz に出力 3.2% 処理済み (2097152 / 65484799 バイト) ……中略…… 99.3% 処理済み (65011712 / 65484799 バイト) 完了 (65484799 / 65484799 バイト) 65484799 -> 51325639 バイト (78.4%) ==> D:\EB_DICT\KAN_PIL_CHIE99\.\AGE01\START を圧縮 <== .\AGE01\START.ebz に出力 6.0% 処理済み (2097152 / 34891776 バイト) ……中略…… 96.2% 処理済み (33554432 / 34891776 バイト) 完了 (34891776 / 34891776 バイト) 34891776 -> 17802195 バイト (51.0%) ==> D:\EB_DICT\KAN_PIL_CHIE99\.\LANGUAGE を圧縮 <== .\LANGUAGE.ebz に出力 完了 (12288 / 12288 バイト) 12288 -> 4121 バイト (33.5%) ==> D:\EB_DICT\KAN_PIL_CHIE99\.\CATALOG をコピー <== .\CATALOG に出力 入力と出力ファイルが同一なので、処理しません
※ebzipの-lオプション引数は0~5を指定可能。5で圧縮率最高になるが、検索時の処理が重くなる。
【4】 EBタイトルディレクトリ内に「START.ebz」(圧縮済データ)ができていれば、同一ディレクトリ内の「START」(元データ)は削除して構わない(下記※参照)。「LANGUAGE.ebz」ができていれば、そのディレクトリの「LANGUAGE」も消してOK。
※ 「漢字源/ピルブック/知恵蔵」(YRRS-426)の場合すでにS-EBXA形式で圧縮されているせいか、ebzipで再圧縮すると検索時に誤動作することがあるようだ。「漢字源」「知恵蔵」は前エントリの漢字インデックス付加処理時にデータ伸長されているためebzip圧縮しても問題ないが、ピルブックは元データを残し、START.ebzを消したほうがよい。
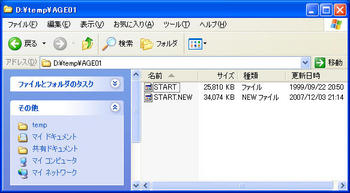
※「漢字源」(漢字インデックス付き)は89788KBが23711KBになった。
【1】 EB Libraryのサイトから「バージョン 4.2.2 の Windows 用インストーラ」を入手、インストール。
【2】 スタートメニューの「ファイル名を指定して実行」を選択し、「cmd」と入力した後「OK」をクリック。コマンドプロンプトを起動し、EBデータ格納ドライブ・ディレクトリに移動する(ここではD:\EB_DICT\KAN_PIL_CHIE99にデータがあるものとする。パラメータは各自の環境に合わせて指定しよう)。
C:\Documents and Settings\username>d: D:\>cd \EB_DICT\KAN_PIL_CHIE99
【3】 コマンドプロンプトでebzipを用いてデータ圧縮。
D:\EB_DICT\KAN_PIL_CHIE99>"C:\Program Files\EB Library\bin\ebzip" -k -f -l 0 ==> D:\EB_DICT\KAN_PIL_CHIE99\.\KANJIGEN\START を圧縮 <== .\KANJIGEN\START.ebz に出力 2.3% 処理済み (2097152 / 91942912 バイト) ……中略…… 98.1% 処理済み (90177536 / 91942912 バイト) 完了 (91942912 / 91942912 バイト) 91942912 -> 24280019 バイト (26.4%) ==> D:\EB_DICT\KAN_PIL_CHIE99\.\PILLBOOK\START を圧縮 <== .\PILLBOOK\START.ebz に出力 3.2% 処理済み (2097152 / 65484799 バイト) ……中略…… 99.3% 処理済み (65011712 / 65484799 バイト) 完了 (65484799 / 65484799 バイト) 65484799 -> 51325639 バイト (78.4%) ==> D:\EB_DICT\KAN_PIL_CHIE99\.\AGE01\START を圧縮 <== .\AGE01\START.ebz に出力 6.0% 処理済み (2097152 / 34891776 バイト) ……中略…… 96.2% 処理済み (33554432 / 34891776 バイト) 完了 (34891776 / 34891776 バイト) 34891776 -> 17802195 バイト (51.0%) ==> D:\EB_DICT\KAN_PIL_CHIE99\.\LANGUAGE を圧縮 <== .\LANGUAGE.ebz に出力 完了 (12288 / 12288 バイト) 12288 -> 4121 バイト (33.5%) ==> D:\EB_DICT\KAN_PIL_CHIE99\.\CATALOG をコピー <== .\CATALOG に出力 入力と出力ファイルが同一なので、処理しません
※ebzipの-lオプション引数は0~5を指定可能。5で圧縮率最高になるが、検索時の処理が重くなる。
【4】 EBタイトルディレクトリ内に「START.ebz」(圧縮済データ)ができていれば、同一ディレクトリ内の「START」(元データ)は削除して構わない(下記※参照)。「LANGUAGE.ebz」ができていれば、そのディレクトリの「LANGUAGE」も消してOK。
※ 「漢字源/ピルブック/知恵蔵」(YRRS-426)の場合すでにS-EBXA形式で圧縮されているせいか、ebzipで再圧縮すると検索時に誤動作することがあるようだ。「漢字源」「知恵蔵」は前エントリの漢字インデックス付加処理時にデータ伸長されているためebzip圧縮しても問題ないが、ピルブックは元データを残し、START.ebzを消したほうがよい。
※「漢字源」(漢字インデックス付き)は89788KBが23711KBになった。
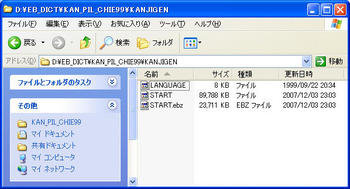
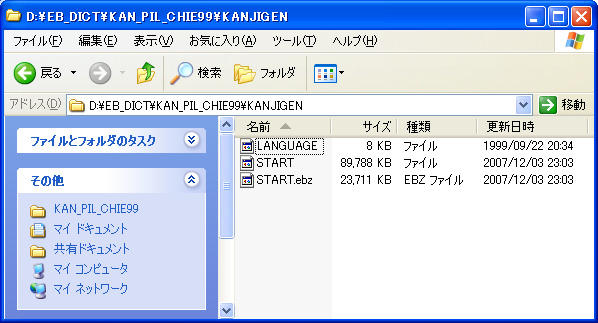
電子ブックに漢字インデックスをつける [PC]
我がアドエスには電子ブック検索アプリ「EBPocket professional」をインストールしている。microSDに入れた各種辞書等の電子ブック(EB)ソフトをいつでもどこでも検索できて至極便利。ただ、EBソフトはおそらく全て生産終了となっているため、オークションサイト等で入手する必要がある(電子ブックの詳細は、Wikipedia内「電子ブック (EB)」を参照)。
先日、EBソフト「漢字源/ピルブック/知恵蔵」(YRRS-426)を手にいれたので、より便利に使うために漢字インデックスを加えてアドエスで使おうと思う。
通常、EBソフトで前方一致・後方一致検索する場合「かな」でしか検索できないが、漢字インデックスを加えれば「漢字」での検索も可能になる。つまり、読めない漢字を(コピペして)引けるようになるということ。
(注:以下の文中の「ディレクトリ」は「フォルダ」と同義)
【1】 EBソフトのキャディからディスクを取り出して、CD(DVD)ドライブに挿入。作業用ディレクトリをHDDに作成し、そこへCD-ROM内のファイルをすべてコピーする(ここではD:\tempを作成)。
※キャディ右側面下のくぼみをシャーペンの先等で押しながら、底部を引っ張ると開く。

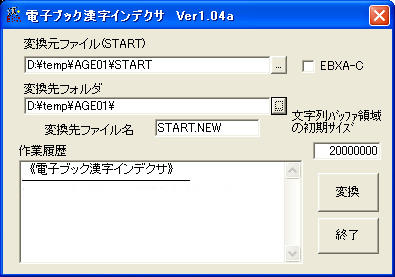
【2】 EB series support pageから「電子ブック漢字インデクサ1.04a」をダウンロードし、インストール。
【3】 「電子ブック漢字インデクサ」を起動し、変換元ファイルと変換先フォルダを指定する。変換元ファイルは【1】でコピーしたファイルのうち「START」を指定。複数タイトルが1枚に収録されているソフトでは、各タイトルのフォルダ内に「START」があるのでそれらをすべて変換。変換先フォルダは、変換元ファイルがあるフォルダを指定すればOK。
※「漢字源/ピルブック/知恵蔵」(YRRS-426)では、漢字源と知恵蔵のみ漢字インデックスの作成に成功。ピルブックにはかなインデックスがないらしく、漢字インデックスを作成できなかった。
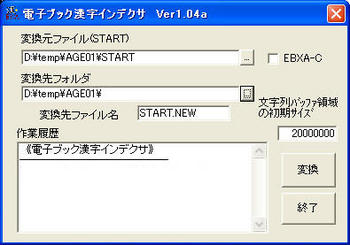
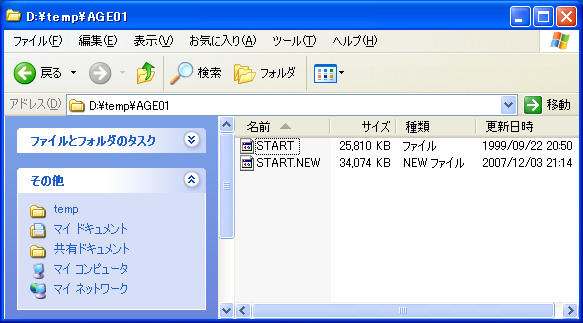
【4】 作業用ディレクトリの各タイトルディレクトリ内に「START」「START.NEW」があることを確認。「START」を削除したあと、「START.NEW」を「START」にリネーム。
ここまでで、漢字インデックス追加作業は完了。作業用ディレクトリを適当な名前にリネームし、アドエスのmicroSDにコピーすればEBPocketでの辞書検索(漢字での前方・後方一致検索)が可能となる。以下、EBWinを使ってPC上で動作確認する方法を記しておく。
【5】 作業用ディレクトリを適当な名前にリネームし、EBWinの辞書格納ディレクトリに移動(またはコピー)。
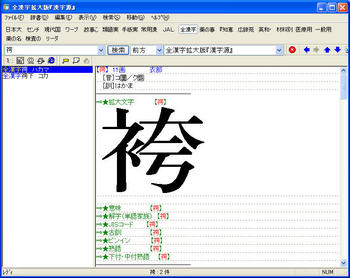
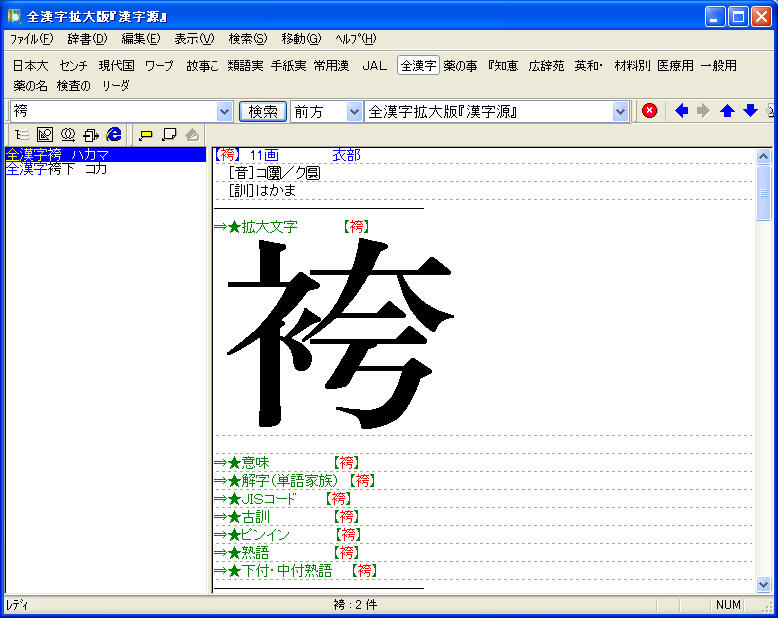
【6】 EBWinを起動し、漢字で前方一致検索ができるか確認。
次のエントリでは電子ブックのデータ圧縮方法を紹介する。
先日、EBソフト「漢字源/ピルブック/知恵蔵」(YRRS-426)を手にいれたので、より便利に使うために漢字インデックスを加えてアドエスで使おうと思う。
通常、EBソフトで前方一致・後方一致検索する場合「かな」でしか検索できないが、漢字インデックスを加えれば「漢字」での検索も可能になる。つまり、読めない漢字を(コピペして)引けるようになるということ。
(注:以下の文中の「ディレクトリ」は「フォルダ」と同義)
【1】 EBソフトのキャディからディスクを取り出して、CD(DVD)ドライブに挿入。作業用ディレクトリをHDDに作成し、そこへCD-ROM内のファイルをすべてコピーする(ここではD:\tempを作成)。
※キャディ右側面下のくぼみをシャーペンの先等で押しながら、底部を引っ張ると開く。

【2】 EB series support pageから「電子ブック漢字インデクサ1.04a」をダウンロードし、インストール。
【3】 「電子ブック漢字インデクサ」を起動し、変換元ファイルと変換先フォルダを指定する。変換元ファイルは【1】でコピーしたファイルのうち「START」を指定。複数タイトルが1枚に収録されているソフトでは、各タイトルのフォルダ内に「START」があるのでそれらをすべて変換。変換先フォルダは、変換元ファイルがあるフォルダを指定すればOK。
※「漢字源/ピルブック/知恵蔵」(YRRS-426)では、漢字源と知恵蔵のみ漢字インデックスの作成に成功。ピルブックにはかなインデックスがないらしく、漢字インデックスを作成できなかった。
【4】 作業用ディレクトリの各タイトルディレクトリ内に「START」「START.NEW」があることを確認。「START」を削除したあと、「START.NEW」を「START」にリネーム。
ここまでで、漢字インデックス追加作業は完了。作業用ディレクトリを適当な名前にリネームし、アドエスのmicroSDにコピーすればEBPocketでの辞書検索(漢字での前方・後方一致検索)が可能となる。以下、EBWinを使ってPC上で動作確認する方法を記しておく。
【5】 作業用ディレクトリを適当な名前にリネームし、EBWinの辞書格納ディレクトリに移動(またはコピー)。
【6】 EBWinを起動し、漢字で前方一致検索ができるか確認。
次のエントリでは電子ブックのデータ圧縮方法を紹介する。
文鳥と3gpp2とYouTube [PC]
au携帯で撮った動画をYouTubeにアップロードしたのだが、頭から15秒しか登録できない(元データはもっと長い)。以前にも同様のトラブルがあったが、仕様だと思ってあきらめていたのだった。
しかし、どうも納得がいかず「youtube」「15秒」「3g2」などのキーワードでググッて原因を調べてみることにした(「3g2」はau携帯の動画フォーマット3gpp2を示す拡張子)。
その結果わかったこと。
・auのEZムービーは最大15秒ごとに分割されている(ムービーフラグメント)。
・ムービーフラグメント非対応アプリでは冒頭15秒しか再生できない。
(ウノウラボより)
つまり、YouTubeが行うflv変換処理がムービーフラグメントに対応していない、ということ?
一方、「QTConverter」を使ってフォーマット変換したものをアップロードすれば、前述の問題をクリアできそうなことも判明した。
「QTConverter」を入手し、「形式:MPEG-4(mp4)、設定:H.264 220kbps 320x240 15fps keyf75, AAC Recommended 80kbps Stereo」としてコンバートしたmp4ファイルをアップロードしてみると、15秒で途切れることなく全て再生できた。……のだが、冒頭数秒間ひどいブロックノイズが入る。QuickTimeでローカルファイルを再生したときには現れないノイズだ。H.264→flv変換時に発生しているのか?
そこで、次のような設定を作成してコンバートしたものをアップロード。3枚目の「ストリーミング設定」は必要ないかもしれない。
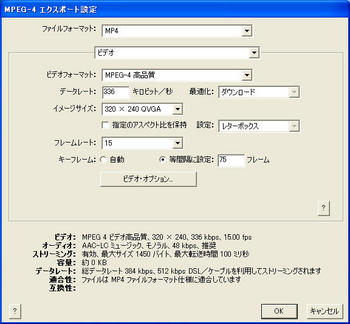
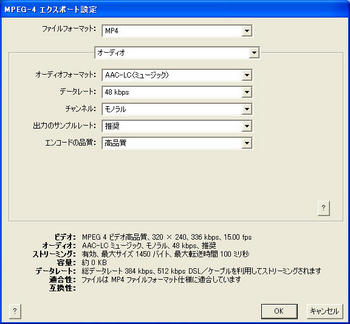
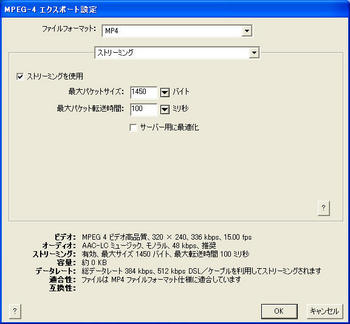
こんな感じになりました。時折ノイズが入りますが、まあまあ成功。
")
しかし、どうも納得がいかず「youtube」「15秒」「3g2」などのキーワードでググッて原因を調べてみることにした(「3g2」はau携帯の動画フォーマット3gpp2を示す拡張子)。
その結果わかったこと。
・auのEZムービーは最大15秒ごとに分割されている(ムービーフラグメント)。
・ムービーフラグメント非対応アプリでは冒頭15秒しか再生できない。
(ウノウラボより)
つまり、YouTubeが行うflv変換処理がムービーフラグメントに対応していない、ということ?
一方、「QTConverter」を使ってフォーマット変換したものをアップロードすれば、前述の問題をクリアできそうなことも判明した。
「QTConverter」を入手し、「形式:MPEG-4(mp4)、設定:H.264 220kbps 320x240 15fps keyf75, AAC Recommended 80kbps Stereo」としてコンバートしたmp4ファイルをアップロードしてみると、15秒で途切れることなく全て再生できた。……のだが、冒頭数秒間ひどいブロックノイズが入る。QuickTimeでローカルファイルを再生したときには現れないノイズだ。H.264→flv変換時に発生しているのか?
そこで、次のような設定を作成してコンバートしたものをアップロード。3枚目の「ストリーミング設定」は必要ないかもしれない。
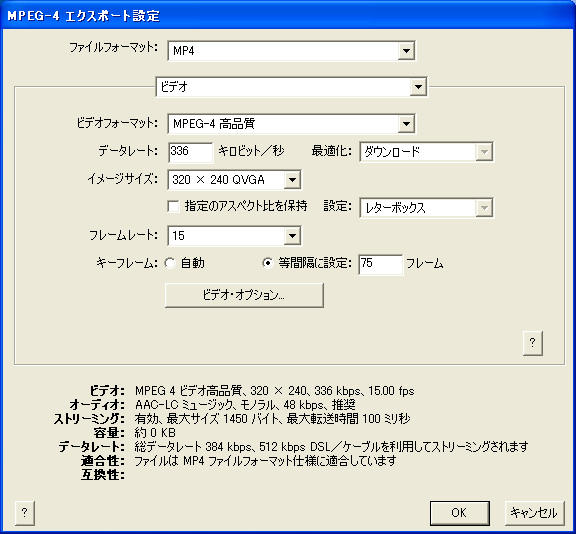
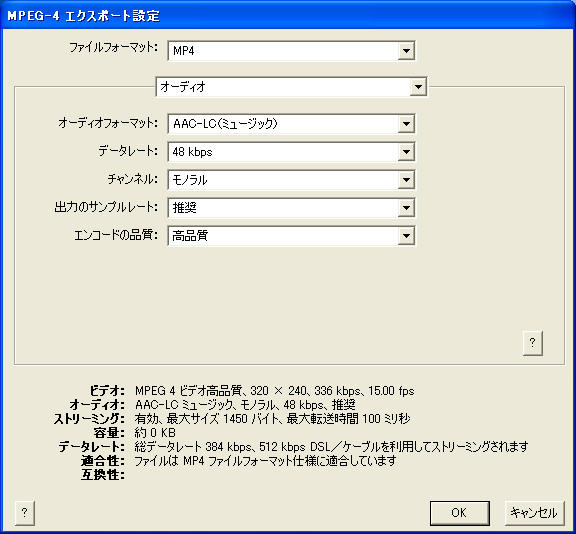
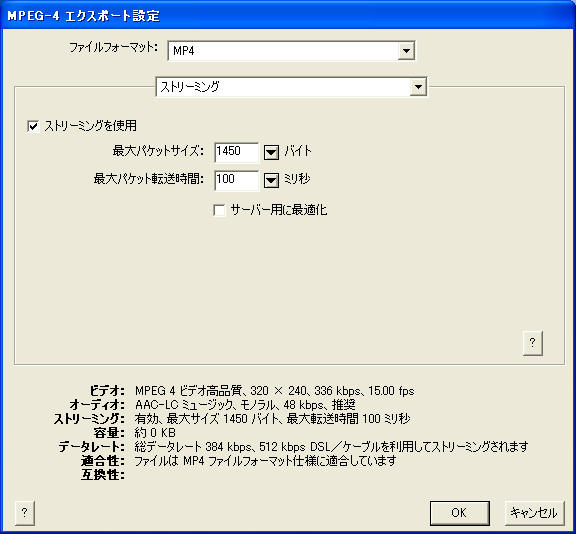
こんな感じになりました。時折ノイズが入りますが、まあまあ成功。
すぴすぴ事情―白文鳥偏愛日記 (花とゆめCOMICSスペシャル)
- 作者: 立花 晶
- 出版社/メーカー: 白泉社
- 発売日: 2008/09/05
- メディア: コミック